Video로 학습한 Image Encoder는 무엇이 달라야 하는가?
오늘은 video를 보고 학습한 image encoder가 image만 보고 학습한 image encoder에 비해 어떤 자질을 가져야 하는지에 대해 내 생각을 정리해보고자 한다.
1. 인간의 지각 과정에 대한 가설
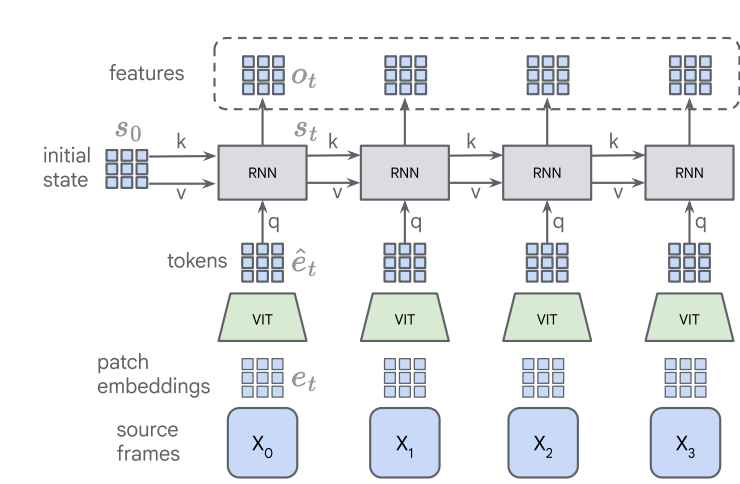
나는 인간의 지각(perception)이 다음과 같은 과정으로 형성된다고 생각한다.
- 우리는 현재 프레임과 과거 프레임들을 각각 image encoder를 통해 latent space로 임베딩하고,
- 이후 RNN, Transformer와 같은 정보 교환 모듈을 통해 이 latent들 사이에서 정보를 통합한다.
그 결과로 형성되는 것이 바로 현재 시점의 지각이다.
이렇게 만들어진 현재의 지각은 이후 다양한 방식으로 활용될 수 있다. 예를 들면,
- 현재 프레임 내에서 중요한 요소를 분석하는 spatial task
- segmentation과 같은 dense prediction
- 과거 프레임과의 비교를 통해 변화나 사건을 포착하는 temporal task
- 미래 프레임 예측
- video action classification
즉 perception은 단일 이미지의 정보를 알아내는 것 뿐만 아니라, 시간을 따라 축적·통합된 표현이라고 볼 수 있다.
2. Noise Box 예제
우리가 video에서 정보를 인지하게 되는과정을 예제를 통해 이해해보자
Recurrent Video Masked Autoencoders
We present Recurrent Video Masked-Autoencoders (RVM): a novel approach to video representation learning that leverages recurrent computation to model the tempo- ral structure of video data. RVM couples an asymmetric masking objective with a transformer-bas
rvm-paper.github.io
위의 프로젝트 페이지에 가면, 다음과 같은 예제를 하나 볼 수 있다.

프로젝트 페이지에 등장하는 noise box가 왼쪽에서 오른쪽으로 이동하는 영상이다.
단일 이미지만 보았을 때는 화면 안에 유의미한 객체가 있다고 판단하기 어렵다.
그러나 여러 프레임을 연속으로 보면, 우리는 noise 속에서 움직이는 box의 존재를 인식하게 된다.
이 예제에서 중요한 질문은 다음이다.
이때 image encoder와 정보교환 모듈은 각각 어떤 역할을 담당하고 있을까?
먼저, 이 상황에서 image encoder가 수행하는 역할은 크게 두 가지라고 생각한다.
(1) Spatial 정보를 충실하게 인코딩하는 역할
객체의 형태, 위치, 질감 등 한 프레임 안에 존재하는 시각적 구조를 잘 표현하는 능력이다.
(2) 프레임 간 정보 교환이 쉬운 embedding을 제공하는 역할
RNN이나 Transformer와 같은 temporal 모델이
시간 축을 따라 정보를 통합하고 비교하기 쉬운 **표현 공간(latent space)**를 만들어주는 것이다.
중요한 점은, image encoder 자체가 box의 존재를 인식하는 것은 아니라는 사실이다.
실제로 의미 있는 box의 존재를 인지하는 것은,
image encoder가 만든 embedding들을 입력으로 받아 시간적 정보를 통합하는 temporal 모델의 역할이다.
아무리 video로 학습한 image encoder라고 해도,
단일 이미지만 보고 저기에 box가 있다고 판단할 수는 없다.
이 한계를 명확히 인지하는 것이 중요하다.
-----------------------------------------------------------------------------------------------------------------------------------------------------
그렇다면 Video를 보고 학습된 image Encoder는 image만 보고 학습된 image encoder에 비해 무엇이 달라야 할까?
이제 핵심 질문으로 돌아가 보자.
image만 보고 학습한 image encoder에 비해,
video를 보고 학습한 image encoder는 무엇이 달라야 할까?
기존의 image encoder들은 첫 번째 역할, 즉 spatial encoding에서는 이미 매우 뛰어나다.
그러나 두 번째 역할에서는 한계가 있다.
이들은 과거 프레임이나 미래 프레임과의 상호작용 속에서 학습된 적이 없기 때문에,
시간적으로 일관된(consistent) 표현을 만들거나,
프레임 간 정보 교환에 적합한 embedding을 학습하는 데 제한이 있다.
그 결과, 뒤에 붙는 RNN이나 temporal module이
프레임 간 정보를 효과적으로 주고받는 데 어려움을 겪게 된다.
따라서 비디오 데이터에 접근 가능한 상황에서의 image encoder는,
단순히 한 장의 이미지를 잘 표현하는 것을 넘어서,
미래 프레임 및 과거 프레임과 정보를 잘 교환할 수 있는 embedding을 만들어내는 성질
을 추가적으로 학습해야 한다고 생각한다.
즉, video로 학습한 image encoder의 가치는,
시간 축을 따라 정보가 자연스럽게 흘러갈 수 있는 표현 공간을 만드는 능력에 있다.
그래서 가끔 video로 학습한 image encoder가 affordance를 배운다는 말을 하기도 하는데,
이것도 결국 시간 축을 따라 정보가 자연스럽게 흐를 수 있는 표현 공간을 학습하다 보니,
행동이 가능한 객체들에 대한 정보가 embedding 안에서 상대적으로 더 중요하게 담기게 되는 결과가 아닐까 싶다.
'AI 기본 지식' 카테고리의 다른 글
| Categorization of Self-Supervised Learning Methods for Computer Vision (0) | 2026.01.29 |
|---|---|
| cosine similarity vs L2 (0) | 2026.01.26 |
| PyTorch에서 모델을 Save / Load하는 방식 (0) | 2026.01.21 |
| Pytorch로 딥러닝 훈련할 때 weight가 업데이트 되는 process (0) | 2026.01.21 |
| invariant vs equivariant (0) | 2026.01.20 |