오늘은 Object-Centric Learning with Slot Attention에서 제안한 방법을 공부해보려고 한다.
https://arxiv.org/abs/2006.15055
Object-Centric Learning with Slot Attention
Learning object-centric representations of complex scenes is a promising step towards enabling efficient abstract reasoning from low-level perceptual features. Yet, most deep learning approaches learn distributed representations that do not capture the com
arxiv.org
Motivation
같은 객체에 속한 patch 들이 비슷한 representation을 갖도록, self-supervised 방식으로 학습할 수 없을까?
이 논문은 바로 이 질문에서 출발한다.
Method
Inductive Bias
서로 다른 객체 20개가 그려진 이미지를, 사람 10명이 보고 기억한 뒤 함께 모여 원본 이미지를 복원하려 한다고 가정해보자.
이때 가장 효율적인 전략은 무엇일까?
모든 사람이 이미지 전체를 기억했다가 다시 그리는 것보다는,
각 사람이 서로 다른 객체 몇 개씩을 맡아 기억하는 것이 훨씬 쉽고 효율적일 것이다.
이 논문은 바로 이러한 객체 단위 분업 구조를 inductive bias로 삼는다.
즉, 이미지를 구성하는 요소들을 객체 단위로 나누어 표현하도록 모델을 유도하는 것이다.
How to Train the Model
훈련 과정은 다음과 같이 진행된다.
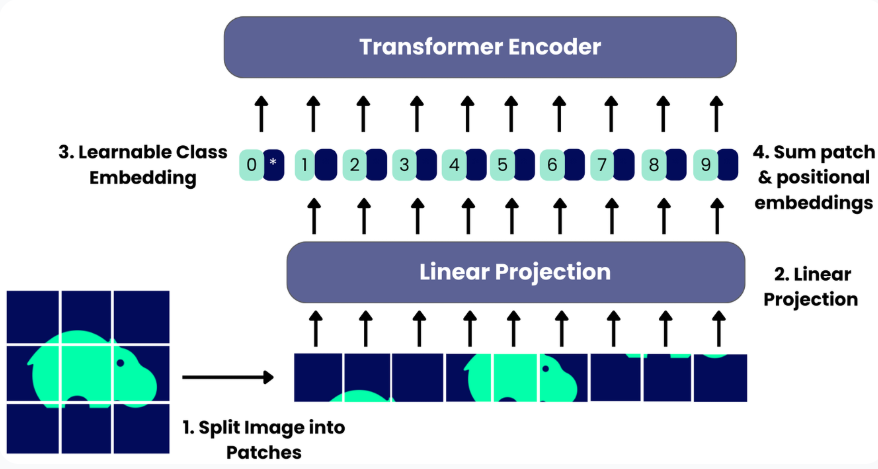
1. 입력 이미지 를 patch 단위로 나눈 뒤, ViT 기반 image encoder에 통과시켜 개의 visual token representation을 얻는다.

2. 정규분포에서 개의 벡터를 랜덤하게 샘플링하여, 이를 query (slot) 로 사용한다. 이 slot들은 learnable parameter는 아니다. 그냥 sampling된 상수 벡터이다.
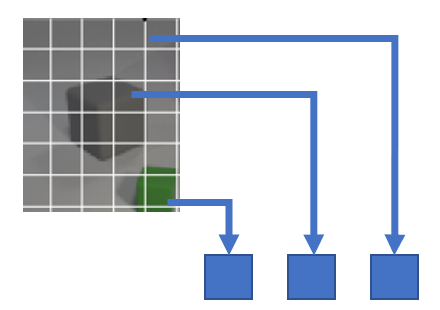
3. visual token들을 key, value로 두고, slot들을 query로 사용하는 cross-attention을 수행한다.
이때 중요한 제약이 하나 있다.
각 patch(key)에 대해, 모든 slot(query)에 대한 attention weight의 합이 1이 되도록 softmax를 적용한다.
즉, 각 patch가 자신이 속할 slot 하나를 선택하는 구조라고 볼 수 있다.

4. 이후 각 slot은, 자신을 선택한 patch들의 정보를 attention weight에 따라 aggregation한다.
쉽게 말해, slot이 자신에게 할당된 patch들의 정보를 모아 하나의 representation을 만드는 과정이다.
5. 위의 3–4 과정을 정해진 횟수(보통 3~7회) 반복한다.
6. 최종적으로 각 slot은 특정 patch들의 representation의 weighted average로 수렴할 것이다.
이후 각 slot을 decoder에 통과시켜서 각각 하나의 이미지 component를 생성하고,
모든 slot이 만든 이미지를 sum하여 원본 이미지를 복원한다.
이때 복원된 이미지와 원본 이미지 사이에 L2 loss를 적용해 학습한다.
이게 어떻게 학습이 되는 걸까?
난 논문 읽자마자 그냥 이게 학습이 되나? 라는 생각이 가장 많이 들었다. 그냥 학습이 어떻게 가능한지, 학습 과정에서 뭐가 어떤식으로 학습이 되길래 최종적으로 잘 훈련이 되는지 전혀 감이 안왔다. 근데 여기서 이해를 위한 킥은 이거 훈련 과정을 생각해보면, 놀랍게도 K means clustering 같은 EM algorithm based clustering을 딥러닝으로 옮겨놓은거랑 똑같다.
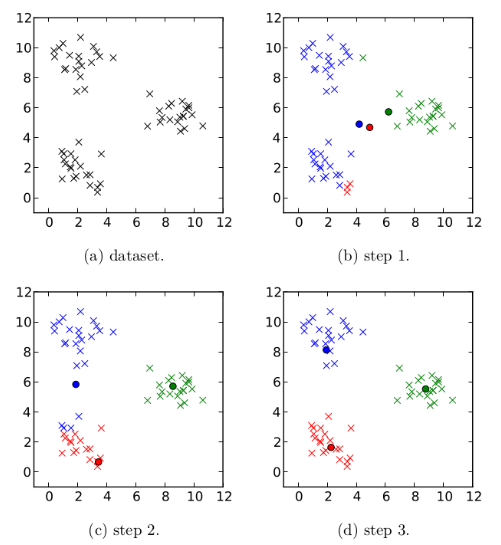
- 처음에 랜덤한 중심점들(slot)을 준다.
- 각 데이터 포인트(patch)는 가장 잘 맞는 중심점(slot)에 할당된다.
→ attention 과정 - 각 중심점은, 자신에게 할당된 포인트들의 평균으로 업데이트된다.
→ slot update - 이 과정을 반복한다.
즉, 전체 과정을 보면
slot 개수만큼 latent에서 patch들을 clustering하고, cluster의 중심점들을 이용해 reconstruction을 수행하는 구조라고 이해할 수 있다.
이러한 상황에서 reconstruction이 잘 되려면, 아까 inductive bias를 떠올려보았을 때,
patch들이 latent에서 의미 있는 방식으로(이상적으로는 객체 단위로) clustering 되어야 한다.
이를 위해 image encoder는, 객체 단위로 분리가 쉬운 latent representation을 학습하도록 자연스럽게 유도된다.
Experiments
논문에서 사용한 데이터셋은 비교적 toy한 환경이지만,
학습된 encoder와 slot attention을 이용해 patch-to-slot assignment를 시각화해보면
각 slot이 서로 다른 객체를 담당하고 있는 모습을 확인할 수 있다.
앞서 말했듯, 이는 patch를 image encoder를 이용해서 latent space로 보낸 뒤 clustering한 결과라고 생각하면 이해하기 쉽다.

Comments
EM algorithm과 이렇게 직접적으로 연결되는 구조라는 점이 굉장히 인상적이었다.
한편으로는, 이 방식이 더 복잡한 자연 이미지나 현실적인 데이터셋에서도 얼마나 잘 동작할지가 궁금해진다.