오늘 이 게시물에는 Token Bottleneck : One Token to Remember Dynamics라는 논문에 대해서 리뷰해보도록 하겠다. 논문 내용에 대해서 그대로 리뷰하진 않았고, 내 개인적인 해석이 상당히 많이 포함되어있으니, 고려해서 글을 읽길 바란다.
https://arxiv.org/abs/2507.06543
Token Bottleneck: One Token to Remember Dynamics
Deriving compact and temporally aware visual representations from dynamic scenes is essential for successful execution of sequential scene understanding tasks such as visual tracking and robotic manipulation. In this paper, we introduce Token Bottleneck (T
arxiv.org
Background
대부분의 로봇 task에서는 시각 정보가 필수적으로 사용된다. 일반적으로 로봇에 부착된 카메라로 촬영한 이미지를 raw visual input으로 받아, 이를 image encoder에 통과시켜 image embedding을 추출한다. 이렇게 얻어진 image embedding은 이후 policy network의 입력 중 하나로 사용되며, 로봇의 행동을 결정하는 데 중요한 역할을 한다. 따라서 로보틱스 task에서 좋은 성능을 얻기 위해서는, 장면에 담긴 정보를 풍부하게 표현할 수 있는 image embedding을 학습하는 것이 매우 중요하다.
다행히도 지난 수년간 CLIP, DINO, EVA 등과 같은 self-supervised learning 기반 비전 모델들이 크게 발전하면서, 장면에 담긴 정보를 풍부하게 표현하는 image embedding을 얻는 것 자체는 더 이상 어려운 문제가 아니라고 생각했다. 그러나 이러한 모델들로부터 얻은 embedding을 그대로 로봇 task에 사용해보면, 기대와 달리 성능이 충분히 잘 나오지 않는 경우가 많았다.
이 논문은 겉보기에는 거의 완벽해 보였던 기존 비전 모델들의 embedding이 로봇 task를 해결하는 데 있어 어떤 핵심적인 정보를 놓치고 있는지를 분석하고, 그 부족한 정보를 명시적으로 담아낼 수 있는 새로운 embedding을 학습하는 것을 목표로 한다.
Motivation
자, 그렇다면 기존의 self-supervised learning 기반 비전 모델들은 도대체 무엇을 놓치고 있었을까? DINOv3 논문을 보면, 단순한 segmentation task조차 놀라울 정도로 잘 수행하는데 말이다.
이 논문은 그 이유를 기존 embedding이 장면 속 객체들의 temporal information 즉, 행동 가능성(affordance)를 충분히 담고 있지 못하기 때문이라고 설명한다. 즉, 기존 embedding들은 정적인 장면에서 객체의 정체성이나 경계, 그리고 객체들 간의 관계는 잘 담아내지만, 그 객체가 다음 순간에 어떻게 움직이거나 변화할 수 있는지에 대한 ‘미래 가능성’을 표현하는 데에는 본질적인 한계가 있다.
보다 구체적인 예를 들어보자. 이미지 안에 손잡이가 있을 때, DINO는 이 손잡이가 보통 문에 부착되어 있다는 사실, 주변 사물들과의 공간적 관계, 그리고 손잡이의 정확한 영역이 어디까지인지는 매우 잘 파악한다. 하지만 이 손잡이가 다음 순간에 어떤 상태로 있을지와 같은 정보는 embedding에 거의 포함되어 있지 않다.
결과적으로, 기존 self-supervised learning 모델들은 장면의 정적인 구조와 의미적 정보는 잘 포착하지만, 로봇이 실제로 상호작용하는 데 중요한 객체들의 행동 가능성(affordance)에 관한 정보는 충분히 담아내지 못한다. 따라서, 이 논문에서 제안한 ToBo 모델에서는 embedding이 행동 가능성(affordance)를 충분히 담을 수 있도록 학습을 유도한다.
Method
방법 자체는 간단하다. 먼저 동영상으로부터 30FPS로 프레임을 추출한 뒤, 두 프레임 사이의 간격이 4에서 94 (0.1~3.1s) 사이가 되도록 (Reference Scene,Target Scene)쌍을 구성한다. 이후 Reference Scene을 ViT에 입력하여 하나의 토큰, 즉 CLS token으로 압축한다.
그 다음, 이 CLS token과 Target Scene의 일부 patch들만을 사용해 self-attention을 수행하고, 이를 바탕으로 전체 Target Scene을 예측하도록 학습한다. 다시 말해, 현재 장면을 요약한 표현과 미래 장면의 제한된 관측 정보만으로, 나머지 미래 장면을 복원하도록 유도하는 것이다.

모델의 구조를 살펴보면, 현재 장면을 요약하는 과정에서 모델은 미래 장면을 예측하는 데 필요한 정보 위주로 표현을 압축하도록 학습된다는 것을 알 수 있다. 논문에서는 이러한 특성을 갖는 표현을 temporally aware visual representation이라고 부른다.
즉, 객체가 다음 순간에 어떻게 움직이거나 변화할 수 있는지에 대한 ‘미래 가능성’을 표현하는것이다.
이를 조금 더 구체적으로 생각해보자. 예시 그림을 기준으로 보면, 기존의 DINO 기반 embedding은 “도로 위에 자전거가 있고, 자전거 위에 사람이 타고 있다”와 같이 장면의 정적인 구성과 의미적 정보를 중심으로 표현한다. 반면 ToBo로 학습된 embedding은 여기에 더해, “도로 위에 자전거가 있고, 자전거 위에 사람이 타고 있으며, 자전거가 다음 순간에 이런 형태들로 있을 수 있다”라는 미래 변화 가능성까지 함께 담도록 학습된다.
즉, ToBo의 embedding은 단순히 무엇이 보이는지를 넘어, 앞으로 무엇이 일어날 수 있는지에 대한 정보를 포함하는 표현이라는 점에서 기존 self-supervised visual representation과 본질적인 차이를 갖는다.
Experiments
사실 위에서 설명한 모든 것들은 논리적으로는 말이 되긴 하지만, 진짜 그런지는 알 수가 없다. visualization할 방법도 솔직히 마땅치 않다. 그래서 논문은 ToBo Embedding의 우수성을 입증하기 위해, 다양한 downstream task에서 ToBo Embedding을 사용하고, baseline(DINO 등...)에 비해서 좋은 것을 입증했다.


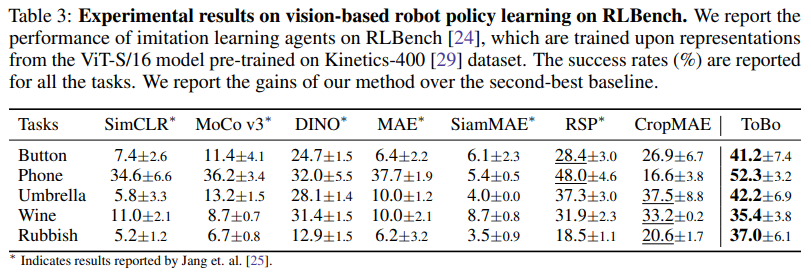
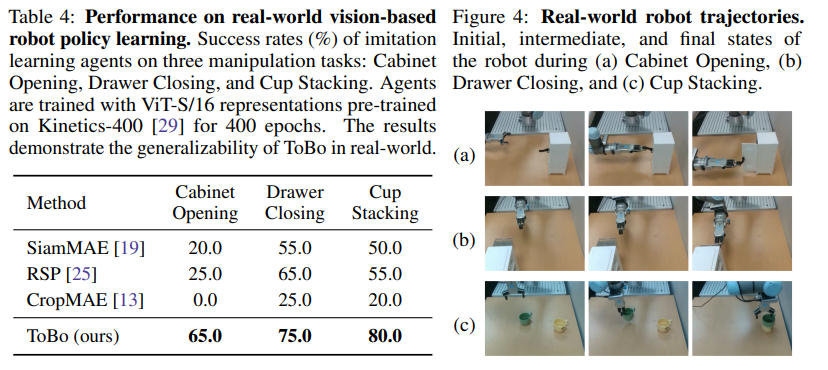
위의 실험들은 로봇 태스크에 ToBo embedding을 활용했을 때의 성능을 보여준다. 예를 들어, 로봇이 컵을 집고, 컵을 움직이는 장면을 ToBo로 학습했다고 가정해보자. 이때 로봇이 컵을 집고 있는 장면에서 embedding을 추출하면, 그 표현에는 단순히 “로봇이 컵을 집고있다”라는 정적인 정보뿐만 아니라, 다음 장면에서 컵의 위치 변화 가능성에 대한 정보까지 함께 반영된다. 물론 DINO와 같은 기존 모델들도 일부 이러한 정보를 담을 수는 있지만, ToBo는 학습 과정 자체가 이러한 정보에 더 집중하도록 설계되어 있다는 차이가 있다.
즉, ToBo로 학습된 embedding은 컵의 위치나 형태만을 표현하는 데 그치지 않고, "컵이 어떻게 이동될 수 있다"는 미래의 변화를 내포한 표현이 된다. 이러한 embedding을 입력으로 사용하는 policy network는, 단순히 물체를 인식하는 단계를 넘어, 이후에 수행될 행동에 직접적으로 유용한 정보를 바탕으로 의사결정을 내릴 수 있게 된다.
결과적으로 ToBo는 정적인 장면만을 보고도 로봇이 이후에 취할 행동을 더 잘 예측할 수 있도록 하는 시각 표현을 제공하며, 이것이 컵을 집는 것처럼 단순해 보이는 태스크에서도 성능 향상으로 이어지는 이유이다.
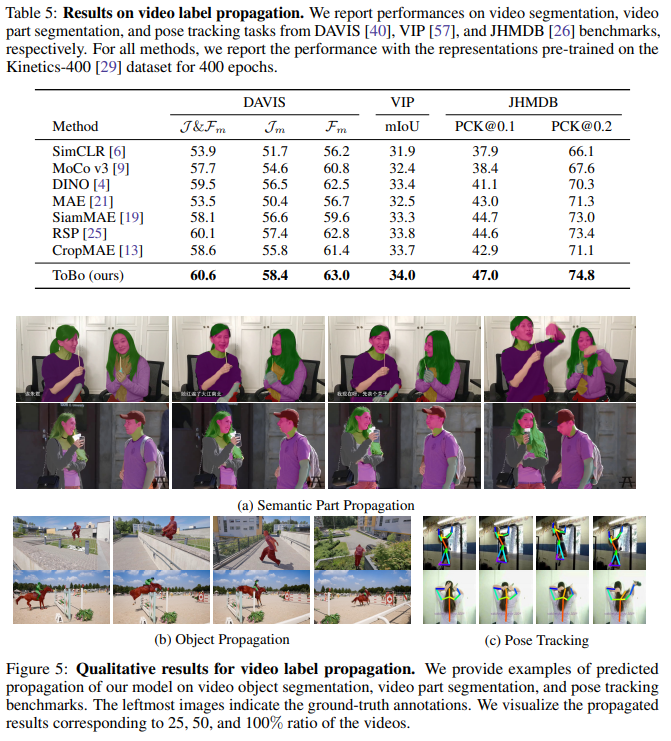
위의 실험들은 Video Vision task를 풀 때, ToBo Embedding의 강력함을 보여준다.
Comments
정말 ToBo Embedding이 object들의 affordance를 제대로 담고 있을까? 그건 아무도 모른다. 근데 그게 아니라면, DINO에 비해서 downstream task의 성능이 잘 나오는 것이 말이 안된다고 생각한다.