오늘 이 게시물에서는 Visual Representation Learning with Stochastic Frame Prediction이라는 논문에 대해서 리뷰해보도록 하겠다.
https://arxiv.org/abs/2406.07398
Visual Representation Learning with Stochastic Frame Prediction
Self-supervised learning of image representations by predicting future frames is a promising direction but still remains a challenge. This is because of the under-determined nature of frame prediction; multiple potential futures can arise from a single cur
arxiv.org
Background
https://seokmin-hardstudy.tistory.com/33
Research Paper Review (ToBo) : Token Bottleneck, One Token to Remember Dynamics
오늘 이 게시물에는 Token Bottleneck : One Token to Remember Dynamics라는 논문에 대해서 리뷰해보도록 하겠다. 논문 내용에 대해서 그대로 리뷰하진 않았고, 내 개인적인 해석이 상당히 많이 포함되어있으
seokmin-hardstudy.tistory.com
위 글의 Background & Motivation 부분에서 확인할 수 있듯이, Robotics task를 위한 visual embedding은 단순히 scene 내 객체들의 경계(boundary)나 객체 간의 관계를 표현하는 데 그쳐서는 안 된다. 나아가, 각 객체가 다음 순간에 어떻게 움직일 수 있는지, 즉 행동 가능성(affordance)에 대한 정보까지 함께 담고 있어야 한다.
그러나 기존의 DINO, SimCLR과 같은 representation learning 기반 embedding들은 주로 정적인 시각적 구조에 초점을 맞추고 있어, 객체가 향후 어떤 행동을 취할 수 있는지에 대한 affordance 정보는 거의 포함하지 못한다는 한계가 있다. 이로 인해, 로봇이 실제 환경에서 행동을 결정하는 데 필요한 정보가 표현에 충분히 반영되지 않는다.
따라서 Robotics task를 효과적으로 수행하기 위해서는, 객체의 외형적 정보뿐만 아니라 행동 가능성까지 내포한 새로운 visual embedding이 필요하다.
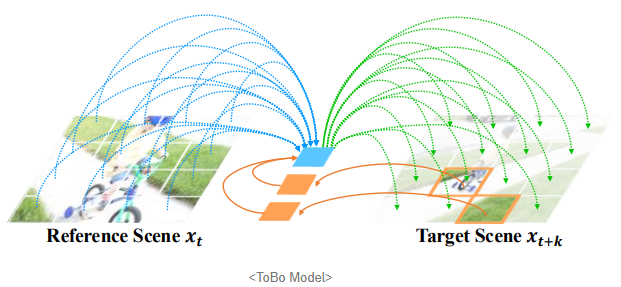
이러한 affordance-aware embedding을 학습하기 위해, 기존 연구들에서는 pretext task로서 다음과 같은 접근을 많이 사용한다. 먼저 현재 frame을 입력으로 받아 이를 encoding한 뒤, 디코더에서 현재 frame의 embedding과 다음 frame에 대한 일부 단서를 함께 사용하여 다음 시점의 frame을 예측하는 방식이다.
이 과정에서 모델은 다음 frame을 정확히 예측하기 위해 필요한 정보를 현재 frame의 embedding에 필연적으로 인코딩하게 된다. 이렇게 훈련된 embedding이 static한 시각 정보를 매우 잘 포착하는 DINO와 같은 방법들이 추출한 embedding보다 robotics downstream task에서 더 나은 성능을 보인다는 점을 고려하면, embedding이 객체의 동적 특성, 즉 향후 어떻게 움직이거나 상호작용될 수 있는지를 나타내는 행동 가능성(affordance)에 관한 정보를 잘 포함했기 때문이라고 해석할 수 있다.
Motivation
이 논문은 기존의 미래 frame 예측 기반 연구들이 encoder embedding에 stochastic한 의미를 충분히 반영하지 못하고 있다는 점을 지적한다. 일반적으로 decoder 단계에서 미래에 대한 추가적인 단서(condition)가 함께 주어지기 때문에, encoder embedding 자체는 가능한 여러 미래 세계들에 대한 정보를 stochastic하게 내포하고 있어야 한다. 그럼에도 불구하고, 기존 방법들은 encoder embedding을 deterministic한 표현으로 고정하고 있으며, 저자들은 이러한 설계가 표현력을 제한하고 결과적으로 성능을 sub-optimal하게 만든다고 주장한다.
이를 보다 직관적으로 이해하기 위해 간단한 예시를 살펴보도록 하겠다.
어떤 scene에서 객체의 affordance 정보가 두 개의 channel에 encoding된다고 가정하자.
- Channel 1: 사과는 움직일 수 있는 물체인가?
- Channel 2: 컵이 움직인다면 얼마나 움직일 수 있는가?
첫 번째 훈련 샘플을 통해 모델이 다음과 같은 embedding을 학습했다고 하자.
| 사과는 움직일 수 있는 물체인가? | 컵은 움직인다면 얼마나 움직이는가? |
| 1 | 3 |
반면, 두 번째 훈련 샘플에서는 다음과 같은 embedding이 관측되었다고 가정하자.
| 사과는 움직일 수 있는 물체인가? | 컵은 움직인다면 얼마나 움직이는가? |
| 0 | -3 |
이 두 샘플을 모두 학습한 후, 해당 이미지에 대한 최종 embedding은 단순 평균에 의해 다음과 같이 수렴하게 된다.
| 사과는 움직일 수 있는 물체인가? | 컵은 움직인다면 얼마나 움직이는가? |
| 0.5 | 0 |
여기서 우리는 본능적으로 어딘가 이상함을 느낄 수 있다. 위와 같은 학습 방식에서는, 서로 다른 가능한 미래들이 단순 평균으로 붕괴(collapse)되어 버리며, 그 결과 embedding이 의미 있는 affordance 정보를 표현하기 어려워진다. 즉, 미래가 본질적으로 multi-modal한 문제임에도 불구하고, 기존의 deterministic한 embedding 학습 방식은 이를 단일한 평균 표현으로 압축해 버리는 구조적 한계를 갖는다.
따라서 이 논문은 객체들의 행동 가능성(affordance)을 평균 압축이 아니라, Stochastic하게 보존할 수 있도록 하는 visual embedding을 학습하는 방법을 제안한다.
Method
이 문제를 해결하기 위한 방법을 생각해보자. 직관적으로 가장 바람직한 방식은, embedding의 각 element가 하나의 속성을 나타내는 scalar 값들의 단순한 벡터가 아니라, 각 속성에 대해 확률적(stochastic) 의미를 갖는 2차원 구조로 표현되는 것일 것이다.
예를 들어, 밑의 예시와 같이 embedding이 속성별로 열(column)을 가지는 2차원 배열로 구성된다고 가정해보자.
첫번 째 열
| P(사과는 움직일 수 있는가?) |
| P(사과는 움직일 수 있는가? = O) |
| P(사과는 움직일 수 있는가? = X) |
두번째 열
| P(컵이 움직일 수 있는 거리) |
| P(컵이 움직일 수 있는 거리 = -2) |
| P(컵이 움직일 수 있는 거리 = -1) |
| P(컵이 움직일 수 있는 거리 = 0) |
| P(컵이 움직일 수 있는 거리 = 1) |
| P(컵이 움직일 수 있는 거리 = 2) |
이 방식의 효과는 간단한 예시로 직관적으로 이해할 수 있다.
첫 번째 데이터에서는 컵이 움직일 수 있는 거리가 -2이고, 두 번째 데이터에서는 컵이 움직일 수 있는 거리가 2라고 하자. 이 두 경우를 함께 학습하면, embedding에서 "컵이 움직일 수 있는 거리"는 deterministic한 embedding일 때 처럼 단일 평균값인 0으로 수렴하는 대신, [0.5, 0, 0, 0, 0.5] 와 같이 서로 다른 가능한 미래를 확률적으로 보존하는 형태로 encoding될 수 있다. 이는 미래가 본질적으로 multi-modal하다는 사실을 embedding 수준에서 직접 반영한 표현이라 볼 수 있다.
그렇다면, embedding이 이렇게 stochastic한 의미를 갖도록 어떻게 강제할 수 있을까?
단순히 embedding의 차원을 N × M으로 늘리는 것만으로는 이 문제가 해결되지 않는다. 만약 모델이 여전히 각 element를 독립적인 scalar 속성으로 해석하며 학습해버린다면, 앞서 Motivation에서 설명한 것처럼 서로 다른 가능한 미래들이 다시 평균으로 붕괴되는 문제가 그대로 발생할 수 있다.
이를 방지하기 위해, 이 논문은 embedding에 구조적인 제약을 추가하는 방법을 제안한다. 구체적으로는, embedding을 N × M 형태로 구성하되, 각 열(column)마다 softmax를 적용하여 해당 열 전체가 하나의 확률분포가 되도록 만든다. 이렇게 하면 모델은 자연스럽게 각 열이 하나의 의미 있는 속성(affordance dimension)을 나타내고, 그 열의 값들이 해당 속성에 대한 확률분포를 표현한다는 구조를 학습하게 된다.
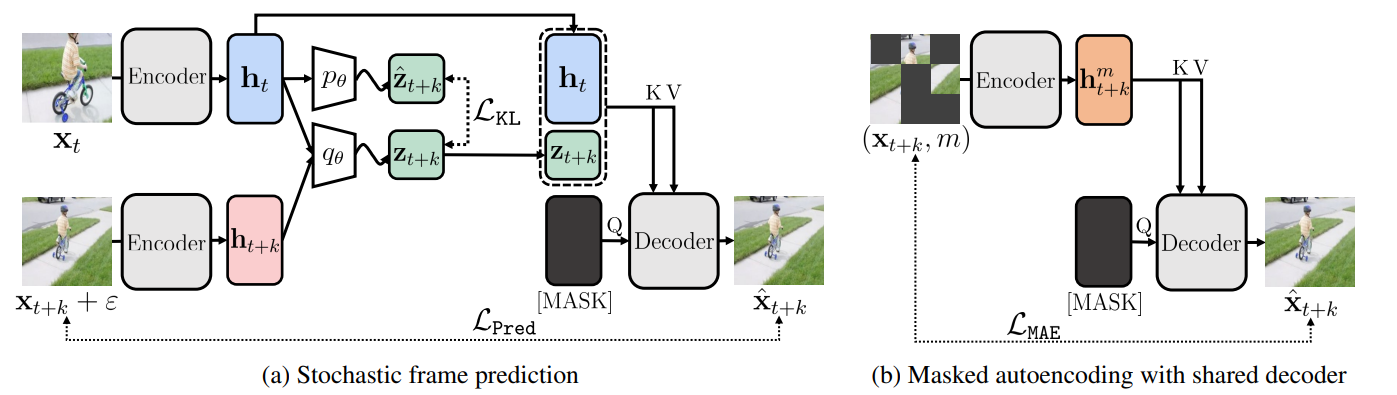
이제 앞서 정리한 배경 지식을 바탕으로, 본격적으로 논문에서 제안하는 모델 구조를 살펴보자.
이 논문에서는 encoder의 weight를 공유한 상태에서 두 가지 task, 즉 task (a)와 task (b)를 동시에 학습하도록 모델을 구성한다. 먼저 task (a)에 집중해서 살펴보자.
Task (a) : 미래 변화 정보를 담은 stochastic embedding 학습

task (a)의 왼쪽 부분을 먼저 살펴보자. 왼쪽 부분의 최종적인 목적은, 오로지 현재 frame으로부터 1) 현재 frame의 시각적 정보를 잘 encoding한 deterministic embedding h(t)와 2) 가능한 다양한 미래 변화들을 확률적으로 내포하는 embedding z(t+k)를 만들어내는 것이다. 이제, 그 과정을 공부해보도록 하자.
먼저 현재 frame인 x(t)와 k step 이후의 frame인 x(t+k)를 각각 동일한 encoder에 통과시킨다. 이를 통해 h(t)와 h(t+k)라는 embedding을 얻는다. 이 embedding들은 각각 현재 frame과 미래 frame의 시각적 정보를 잘 encoding한 deterministic embedding이다.
다음 단계에서는 q라는 별도의 network에 h(t)와 h(t+k)를 함께 입력으로 넣는다. 이 network의 출력은 z(t+k)이며, 저자들은 이 embedding이 현재 frame과 미래 frame 사이에서 발생한 변화 정보를 담도록 설계되었다고 설명한다.
바로 이 z(t+k)가 이 논문의 핵심인 stochastic embedding이다. 학습 과정에서 모델은 하나의 h(t)에 대해 여러 가능한 h(t+k)를 관측하게 되며, 그 결과 z(t+k)는 단일한 변화가 아닌, 가능한 다양한 미래 변화들을 확률적으로 내포하는 표현으로 학습된다.
downstream task에서는 미래 frame x(t+k)을 볼 수 없기 때문에, z(t+k)를 오로지 h(t)만 보고 만들어 낼 수 있어야 한다. 이를 위해 논문에서는 q로부터 생성된 분포와, h(t)만을 입력으로 하는 p라는 prior 분포를 KL divergence로 정렬시키는 방식을 사용한다.
즉, 훈련 때는 h(t)와 q로부터 만든 z(t+k)를 decoder에 전달하고, inference를 할 때에는 h(t)와 p로부터 만든 z(t+k)를 활용하는 것이다.
이후 decoder에는 h(t)와 z(t+k)가 함께 입력으로 주어진다. 이때 z(t+k)는 decoder 학습의 안정성을 위해서 q로부터 생성된 것으로 사용한다.
decoder는 완전히 아무 정보도 없는 MASK 상태로부터 h(t)와 z(t+k)를 이용하여 다음 frame을 예측해야 한다.
- h(t): 현재 frame이 어떤 장면인지를 나타내는 정보
- z(t+k): 현재 frame에서 미래로 넘어가면서 발생할 수 있는 변화에 대한 정보
이 두 가지를 함께 사용하여 다음 frame을 복원하도록 학습하는 것이다.
Task (b) : static semantic 정보의 보존

task(a)만 가지고 학습을 하면, 혹시라도 Encoder가 static한 정보를 embedding에 담는 것을 소홀히 할 수 있기 때문에 task(b)에서는 (a)와 공유하는 encoder로 MAE문제를 푼다.
Method : Downstream task에서의 사용 방식
downstream task에서는 x(t+k)가 주어지지 않는다. 따라서 학습이 끝난 이후 실제 활용 단계에서는,
- h(t)와
- p로 부터 얻은 z(t+k)를 각각 linear layer에 통과시킨 뒤
- 두 embedding을 concat하여 하나의 representation으로 사용한다.
이렇게 구성된 representation은 현재 장면에 대한 정보와, 해당 장면에서 가능한 미래 변화(affordance)에 대한 정보를 동시에 포함하게 된다.
Experiment
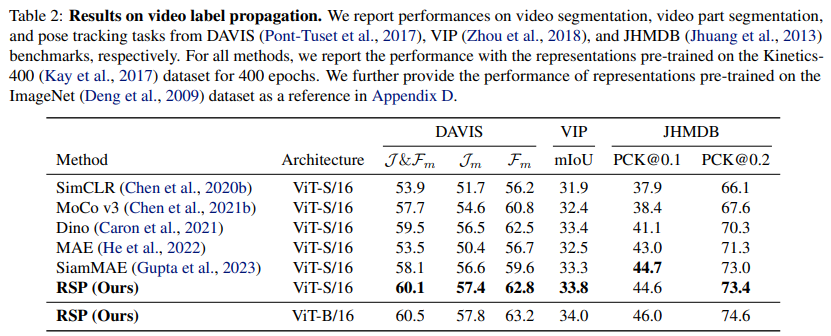
이 논문에서 제안한 방식으로 학습한 embedding을 robotics downstream task와 label propagation과 같은 video vision task에 적용한 결과, 기존의 다른 self-supervised learning 방법들로부터 추출한 embedding을 사용했을 때보다 더 우수한 성능을 보이는 것을 확인할 수 있다.