오늘은 World Models라는 논문에 대해서 가볍게 리뷰해보려고 한다.
https://arxiv.org/abs/1803.10122
World Models
We explore building generative neural network models of popular reinforcement learning environments. Our world model can be trained quickly in an unsupervised manner to learn a compressed spatial and temporal representation of the environment. By using fea
arxiv.org
Preliminary : MDN-RNN
하나의 현재에 대해서 가능한 미래는 여러개 일 수 있다. 따라서 미래 상태를 예측하는 모델을 설계할 때에는 stochastic하게 설계하는 것이 바람직한 방향일 것이다.
MDN-RNN은 미래 상태를 확률적으로(stochastic하게) 예측하기 위한 모델이다. 예를 들어, 어떤 대상의 상태가 시간에 따라 t1 → t2 → t3로 변화하고, 각 시점의 상태가 k차원 벡터로 표현된다고 하자. MDN-RNN의 목표는 이러한 과거 상태들을 바탕으로, 다음 시점인 t4의 state vector를 하나의 고정된 값이 아니라 확률분포의 형태로 추정하는 것이다.
이를 위해 먼저 RNN을 사용하여 과거 시점들의 정보를 누적 반영한 t3 시점의 embedding을 계산한다. 이 embedding은 단순히 t3의 상태만을 나타내는 것이 아니라, t1부터 t3까지의 시간적 맥락을 함께 포함한 표현이다.
이후 해당 embedding을 MLP에 입력으로 전달하고, MLP는 state vector의 각 channel에 대해 Gaussian mixture를 구성하기 위한 파라미터들을 출력한다. 즉, k차원 state vector의 각 channel마다 여러 개의 Gaussian component로 이루어진 확률분포가 정의되며, 이를 통해 각 차원의 값이 다중 모드 형태로 표현될 수 있다.
결과적으로 MDN-RNN은 다음 시점의 state를 하나의 deterministic한 값으로 예측하는 대신, 각 channel이 확률적으로 표현된 state distribution을 모델링함으로써 미래에 발생할 수 있는 여러 가능한 상태들을 자연스럽게 포착한다.

Background
강화학습의 학습 과정을 살펴보면, 에이전트는 하나의 rollout (action₁ → action₂ → … → actionₙ)을 수행한 뒤, rollout이 종료된 이후에 관측된 reward를 기반으로 policy를 업데이트한다. 이때 각 action은 보통 시간에 따라 r^t로 가중되어 학습에 반영된다.
그러나 이러한 방식에는 본질적인 한계가 존재한다. 우리는 trajectory 내의 개별 action들의 기여도를 r^t로 가정하지만, 이 가중치가 실제 기여도를 정확히 반영한다고 보기는 어렵다.
예를 들어, 실제로는 action₂가 최종 reward 형성에 거의 기여하지 않았음에도 불구하고, 전체 rollout이 높은 reward를 받았다면 해당 action 역시 긍정적인 학습 신호로 처리된다. 이와 같은 경우로 인해 policy 업데이트에는 불필요한 노이즈가 포함되게 되며, 이는 강화학습에서 잘 알려진 credit assignment problem이다.
이러한 상황에서 큰 모델을 사용할 경우 문제가 더욱 두드러진다. 모델은 실제로 중요한 신호뿐만 아니라 우연적으로 발생한 노이즈에도 과도한 의미를 부여하며 이를 학습하려고 하게 되고, 그 결과 학습이 불안정해지거나 수렴이 어려워질 수 있다. 물론 충분히 많은 양의 고품질 데이터를 확보할 수 있다면 이러한 문제는 완화될 수 있지만, 강화학습 환경에서 유의미한 데이터를 대량으로 수집하는 것은 일반적으로 쉽지 않다.
이러한 이유로 기존의 강화학습 연구에서는 종종 상대적으로 작은 모델을 사용하여, 노이즈에 해당하는 신호들이 자연스럽게 무시되도록 유도해왔다. (예를 들어 특정 상황에서 3개의 시나리오에서 각각 좌회전, 우회전, 좌회전이라는 값을 내면, 작은 모델은 그냥 단순히 좌회전이라고 배우지만, 큰 모델은 복잡하게 case를 나누고 모델링한다.)
이렇게 작은 모델을 사용하는 것은 학습 안정성을 높이는 데에는 도움이 되지만, 동시에 모델의 표현력을 제한하는 trade-off를 동반한다. 이 논문은 바로 이러한 한계를 문제의식으로 삼아, 강화학습 환경에서도 큰 모델을 안정적으로 사용할 수 있는 방법을 제시하고자 한다.
Method
먼저 이전까지 강화학습 모델들의 구조를 알아보자.

기존의 강화학습 모델들은 대체로 위와 같은 구조를 따른다. 입력으로 들어온 image는 image encoder를 거쳐 embedding으로 변환되고, 이 embedding을 입력으로 받아 policy network가 action을 결정한다. 그리고 이러한 구조에서 image encoder와 policy network를 하나의 모델로 묶어 end-to-end 방식으로 강화학습을 통해 함께 학습시키는 것이다.
논문에서 제안하는 아이디어는 매우 단순하다. image encoder와 policy network의 학습을 분리하자는 것이다. 구체적으로, image encoder는 강화학습이 아닌 self-supervised learning을 통해 사전에 학습시키고, 강화학습 단계에서는 policy network만을 학습 대상으로 사용한다. 앞서 논의한 credit assignment problem을 고려하면, 강화학습으로 학습되는 네트워크는 가급적 작은 것이 유리하다. 따라서 큰 모델을 사용할 수 있으려면, 그 모델은 강화학습으로 훈련시키면 안된다. 따라서 이 논문은 image encoder를 강화학습의 noisy한 학습 신호로부터 분리하고, self-supervised learning을 통해 안정적으로 학습시킴으로써 큰 모델을 사용할 수 있도록 한다. 오늘날에는 자연스럽게 받아들여지는 접근이지만, 이 논문이 발표된 2018년 당시에는 비교적 새로운 관점이었다.
여기에 더해 논문은 한 가지 아이디어를 추가로 제안한다. policy network의 입력으로 현재 frame의 image embedding뿐만 아니라, 미래 frame의 embedding을 확률적으로(stochastic하게) 예측한 표현을 함께 제공하자는 것이다. 미래에 대한 정보를 내포한 표현이 주어질 경우, policy network는 현재 상태에서 어떤 행동이 바람직한지를 더 쉽게 판단할 수 있을 것이라는 직관에 기반한 설계이다.
이제 논문에서 제안한 구조를 조금 자세히 살펴보자.
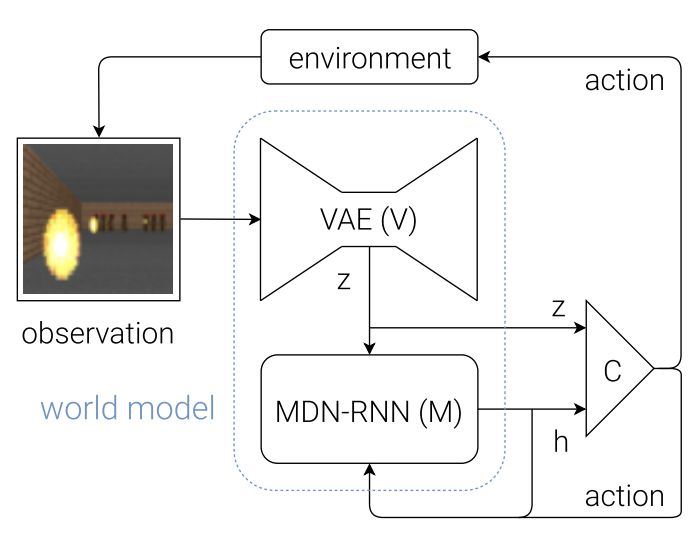
먼저 VAE를 이용해 시각 입력을 self-supervised 방식으로 학습한다. 이 과정에서 VAE는 입력 데이터를 저차원의 latent representation으로 압축하도록 훈련되며, 학습이 완료된 이후에는 VAE의 encoder를 embedding 추출기로 사용한다.
이후 현재 시점의 latent vector z와 과거의 정보들(RNN state)을 바탕으로, 다음 시점의 (latent z) = h를 확률적으로 예측하는 모델 MDN-RNN을 self-supervised로 훈련한다.
강화학습시에는 이렇게 얻어진 현재 z와 MDN-RNN이 예측한 미래 latent 표현 h를 함께 controller, 즉 policy network의 입력으로 제공하고, controller는 이를 바탕으로 action을 결정하여 환경과 상호작용한다.
중요한 점은 학습 방식의 분리이다. VAE와 MDN-RNN은 모두 self-supervised learning을 통해 사전에 학습되며, 강화학습 단계에서는 controller만을 대상으로 policy optimization을 수행한다. 이를 통해 강화학습의 noisy한 학습 신호가 표현 학습 단계에 직접적으로 영향을 미치지 않도록 설계되어 있다.
Experiment : Car Racing Experiment
위의 방식을 이용해서 Car Racing Experiment에서 sota를 달성했다고 한다.


Comment
미래를 stochastic하게 예측해야하는 것은 확실한 것 같다.
다만 흥미로웠던 점은, 단순히 autoencoder로 학습한 정적인(static) embedding의 미래 값을 예측하여 controller에 입력으로 제공하는 것만으로도 성능이 크게 향상된다는 사실이다.
예측된 값이 비록 미래 시점의 state embedding이기는 하지만, embedding 자체는 정적인 시각 정보만을 담고 있을 가능성이 크며, 객체의 행동 가능성(affordance)과 같은 동적인 정보가 포함되어 있다고 보기는 어렵다. 그럼에도 불구하고 이러한 접근만으로도 성능 향상이 크게 관측된다는 것은, 미래의 시각적 상태에 대한 정보 자체가, 비록 정적인 표현일지라도, policy가 행동을 결정하는 데 있어 상당히 유용한 단서를 제공하고 있음을 시사한다.
이러한 맥락에서, 만약 VAE 대신 DINO와 같이 정적인 시각 표현을 더욱 강력하게 학습하는 representation learning 방법을 사용했다면, 성능이 어느 정도까지 향상될 수 있었을지도 자연스럽게 궁금해진다.